


La croissance des outils d'intelligence artificielle (IA) et des modèles d'apprentissage automatique (ML) dans le criblage de médicaments a considérablement augmenté le nombre de cibles thérapeutiques viables tout en réduisant les délais de mise en marché. Ce virage a alimenté l'essor des laboratoires secs (dry labs)—des environnements informatiques où les simulations et les analyses mathématiques remplacent les pipettes, les réactifs et les spectromètres des laboratoires humides (wet labs) traditionnels.
Au Canada, cette évolution a engendré un défi géographique unique. Bien que Toronto se soit imposée comme une plaque tournante mondiale des laboratoires secs et de l'IA (soutenue par l'Institut Vector et la Data Science Coalition de Roche), un goulot d'étranglement persiste. Une fois qu'un candidat prometteur est identifié, il se peut qu'il n'y ait aucun espace de laboratoire humide à proximité pour poursuivre sa recherche et son développement. Cette pénurie explique pourquoi la création de nouveaux laboratoires humides dans la région est systématiquement soulignée par les médias spécialisés. Un autre goulot d'étranglement réside dans le fait que les modèles in silico générés par l'IA ne sont pas toujours dans un format qui s'harmonise facilement avec les résultats analytiques des laboratoires humides.
Pour les organisations biopharmaceutiques canadiennes prévoyant une croissance au cours des cinq prochaines années, ce fossé entre le criblage en laboratoire sec et la R&D en laboratoire humide pousse la commercialisation hors de l'Ontario vers d'autres régions disposant d'installations de laboratoire plus appropriées. De plus, les organisations doivent considérer le coût de l’inaction face à cet écart. La saisie manuelle des données augmente les risques et peut entraîner des reprises de travail, des retards réglementaires ou l’échec des transferts technologiques.
Pour réussir la transition entre les laboratoires secs d'une région et les laboratoires humides d'une autre, les organisations canadiennes ont besoin d'une passerelle informatique et de données normalisées. Une passerelle informatique normalisée garantit l'intégrité des données malgré la distance géographique. L'adhésion aux principes ALCOA+ est cruciale lorsque Santé Canada ou la Food and Drug Administration des États-Unis demandent précisément comment un modèle informatique est parvenu à une conclusion spécifique.
Spécialisation géographique: L'Ouest humide vs l'Est sec du Canada
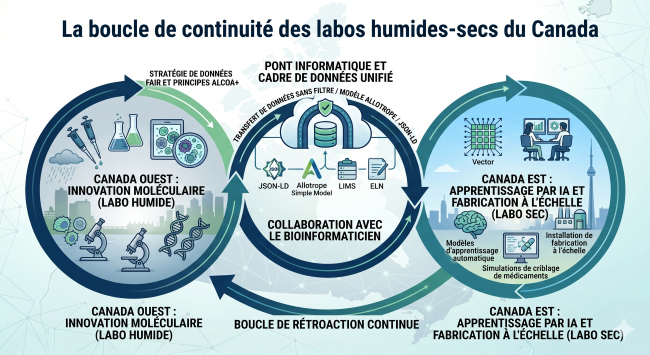
Le climat de Vancouver est réputé pour être humide, tout comme son paysage actuel de laboratoires. Une grande partie de la recherche pharmaceutique préliminaire sur les cibles thérapeutiques identifiées dans la région du Grand Toronto est actuellement menée à 3000 kilomètres de là, dans le Nord-Ouest Pacifique canadien.
Vancouver est devenue un centre d'innovation moléculaire. Des entreprises comme AbCellera, Amgen et STEMCELL Technologies pilotent la recherche de pointe, produisant des quantités massives de données biologiques. De même, plus à l'est, Montréal demeure un bastion de la chimie médicinale, mené par Pharmascience.
À l'inverse, la région du Grand Toronto concentre des informaticiens et des physiciens médicaux, soutenus par des installations comme le Centre MaRS. Les organisations des sciences de la vie de cette région stimulent la conception de radioligands (telles que Fusion Pharmaceuticals et Alpha Cancer Technologies).
Pour les investisseurs et les dirigeants, le message est clair: tournez-vous vers l'Ouest pour la découverte, mais regardez vers l'Est pour l'optimisation par l'IA. Cependant, pour les organisations opérant à travers ces pôles, la distance n'est pas seulement physique—elle est numérique.
Un cadre informatique unifié, incluant l'expertise d'un bio-informaticien, permet aux équipes multidisciplinaires de collaborer en temps réel et dissipe une partie du mystère lié à la boîte noire. Combler cet écart grâce à une équipe multidisciplinaire aide les scientifiques de laboratoire humide à faire confiance aux résultats des modèles d'IA, tout en permettant aux scientifiques de laboratoire sec d'avoir la certitude que leurs données peuvent être vérifiées expérimentalement.
Défi: Briser la cage des données propriétaires
Au-delà de la pénurie d'espaces de laboratoires humides, un autre obstacle entrave la découverte pilotée par l'IA au Canada. Les silos de données sont intentionnellement créés par les formats propriétaires des fournisseurs d'instruments et de systèmes. Les données dans un format propriétaire peuvent être invisibles pour les modèles de ML. Les recherches précieuses effectuées sur une côte doivent être traduites d'une manière ou d'une autre pour être exploitées sur l'autre côte. L'informatique en périphérie (edge computing) et les lacs de données natifs du nuage commencent à s'attaquer à cet obstacle, accélérant l'accès aux résultats des modèles in silico sur les deux côtes.
Pour rester compétitives, les organisations canadiennes doivent adopter une stratégie de données neutre vis-à-vis des fournisseurs. Les données brutes doivent être extraites dans des formats standardisés et agnostique vis-à-vis des fournisseurs tels que l'ASM (Allotrope Simple Model) ou le JSON-LD. Cela permet à une séquence protéique ou à un essai cellulaire généré en Colombie-Britannique et stocké dans un LIMS ou un ELN de devenir prêt pour l'IA dès qu'il atteint un serveur en Ontario. Préserver l'intégrité des données lors de ces transformations est primordial.
Harmoniser la découverte grâce à l'informatique de laboratoire
L'approche traditionnelle de la gestion des données de laboratoire utilise un ELN pour les travaux de découverte et un LIMS pour le contrôle de la qualité. Lorsque ces systèmes ne sont pas interfacés, des silos de données apparaissent. Délaisser les données cloisonnées dans un ELN ou un LIMS aide les organisations à progresser vers un cadre de données unifié. Des données harmonisées et conformes aux principes FAIR comblent le fossé entre la R&D de stade précoce et les exigences du stade clinique.
L'informatique de laboratoire moderne peut avoir recours à une couche intermédiaire (middleware; souvent une plateforme de données scientifiques) qui harmonise les données tout au long du cycle de vie. Cela permet de suivre une molécule depuis sa première simulation informatique (sec) jusqu'à son premier essai en laboratoire (humide), et finalement jusqu'aux essais cliniques, sans perdre le contexte.
L'harmonisation de votre écosystème de données nécessite quelques éléments :
- Schémas de métadonnées normalisés: Ils garantissent que les termes signifient la même chose dans chaque laboratoire du pipeline de recherche de l'organisation. Cela est souvent réalisé grâce à une ontologie.
- Pipelines de données automatisés: Ils transfèrent automatiquement les données du banc d'essai vers le nuage, réduisant ainsi les erreurs humaines et la latence du système.
- Systèmes de conformité agiles: Ils satisfont aux réglementations de Santé Canada et de la FDA américaine sans freiner la mentalité d'innovation rapide (fail fast) de la R&D à l'ère du Labo 4.0.
Gagner la course à l'innovation
Combler le fossé entre les laboratoires humides et secs n'est plus seulement une question de géographie ; c'est une question d'infrastructure numérique. Les organisations canadiennes des sciences de la vie qui domineront la prochaine décennie seront celles qui cesseront de traiter les laboratoires humides et secs comme des silos distincts pour les considérer comme une boucle de données unique et continue.
Comment votre organisation pourrait-elle mieux exploiter les données de ses laboratoires humides et secs?





.png)


.png)

Comments